Public API Documentation
Public integration guides, API reference, and project setup notes for teams evaluating or implementing Paxmod.
Quickstart
Start moderating your projects in under five minutes.
1. Create a Project
The first step to using Paxmod is to create a project. Use the Projects tab on the left, open the Add New menu, and choose a moderation type (Text or Image). Name your project and add a description.
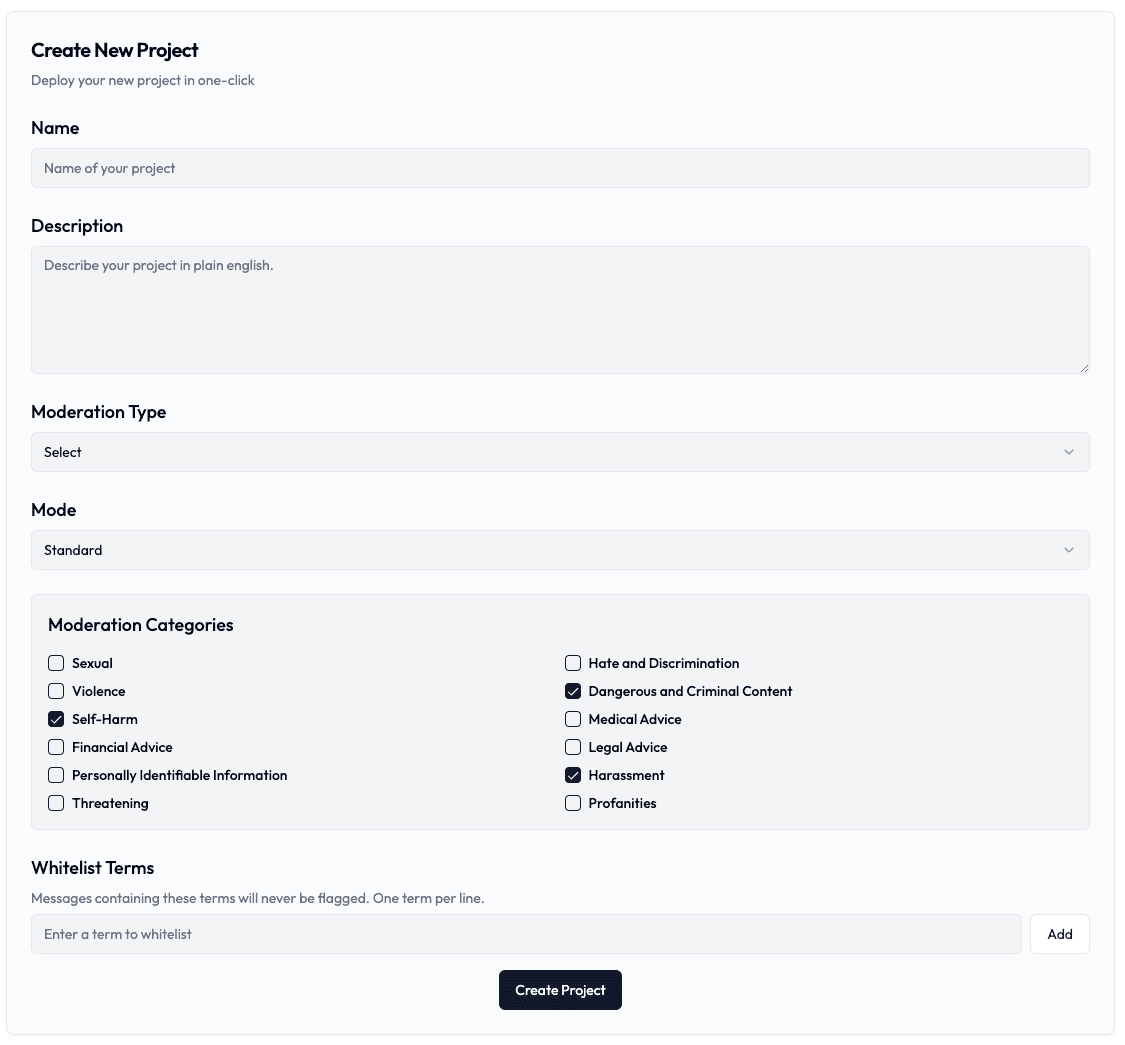
The project description is for your reference only and is not used by the moderation service to analyze or moderate content.
Pax supports both text and image moderation. Image projects use category-based moderation (no advanced policy mode).
2. Adjust Your Project Settings
In standard mode, you can set the thresholds for toxicity, profanity, hate speech, and more. You likely will need to iterate on the thresholds to get the desired results.
The following categories can be configured:
- Sexual
- Hate and Discrimination
- Violence
- Dangerous and Criminal Content
- Self-Harm
- Medical Advice
- Financial Advice
- Legal Advice
- Personally Identifiable Information
- Harassment
- Threatening
- Profanities
- Spam
3. Submit Content for Moderation
Integrate Pax into your application using our simple API. Send content for moderation before it's published to ensure a safe environment for your users.
Example Integration
// Before publishing user content
const checkContent = async (content) => {
const response = await fetch('https://www.paxmod.com/api/v1/text', {
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
},
body: JSON.stringify({
message: content,
user_id: 'optional_user_id',
context_id: 'optional_context_id'
})
});
const result = await response.json();
if (result.content_moderation?.flagged) {
// Handle flagged content
return false;
}
// Content is safe to publish
return true;
}4. Review Flagged Messages
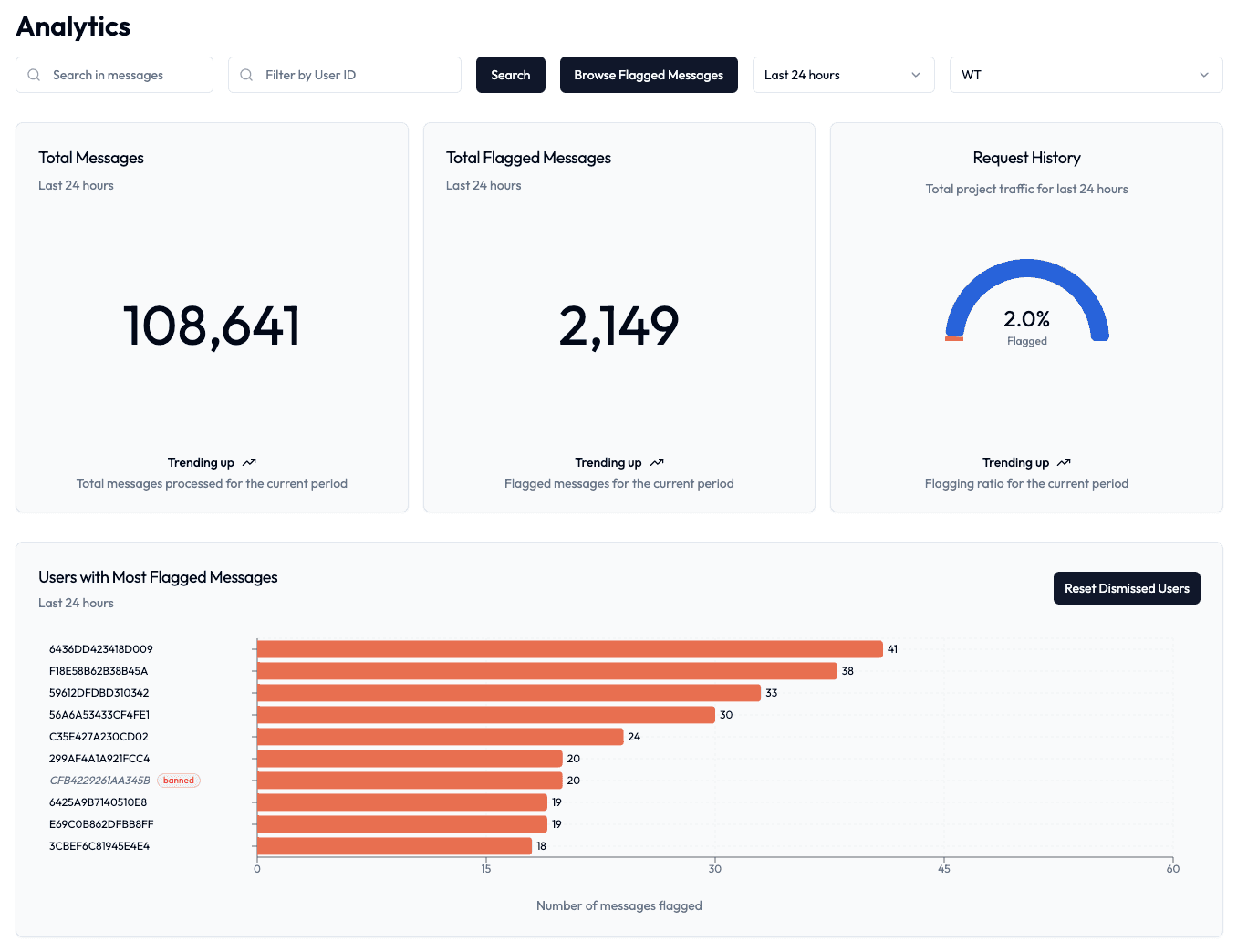
Monitor and review flagged messages in your analytics dashboard. You can:
- View messages flagged by category
- Track messages by user ID and context ID
- Provide feedback on moderation accuracy
- Track moderation performance over time
All Done!
You're done! You are now ready to moderate content using Pax. If you have any feedback or questions, please shoot us an email at contact@paxmod.com
Projects
Learn how to create and manage your content moderation projects.
Text Projects
Set up text content moderation projects.
Image Projects
Set up AI-powered image content moderation.
Project Configuration
Projects can be configured in two modes: standard or advanced. Each mode offers different levels of control over content moderation.
Standard Mode
Configure individual thresholds for specific content categories. Ideal for most use cases where you need granular control over different types of content.
Available Categories:
- Sexual
- Hate and Discrimination
- Violence
- Dangerous and Criminal Content
- Self-Harm
- Medical Advice
- Financial Advice
- Legal Advice
- Personally Identifiable Information
- Harassment
- Threatening
- Profanities
- Spam
Advanced Mode
Define custom moderation policies using natural language. Perfect for complex use cases requiring specific content guidelines.
Features:
- Custom policy definitions
- Single threshold setting
- Natural language rules
- Complex policy enforcement
Project Features
Threshold Management
Adjust sensitivity thresholds (0-1) for each category or policy. Lower values are more permissive, higher values are more strict. The playground allows real-time testing of threshold adjustments.
Available Categories:
- Sexual
- Hate and Discrimination
- Violence
- Dangerous and Criminal Content
- Self-Harm
- Medical Advice
- Financial Advice
- Legal Advice
- Personally Identifiable Information
- Harassment
- Threatening
- Profanities
- Spam
Whitelist System
Add terms or phrases that should never be flagged. Useful for game-specific terminology, character names, or approved content that might otherwise trigger moderation.
Project Playground
Test your moderation settings in real-time. View detailed category scores, adjust thresholds, and see immediate results. Changes in the playground can be saved using the Update Project button.
Image Moderation
Image moderation uses our advanced multimodal AI models to detect harmful visual content. Unlike text moderation, image projects only support category-based moderation (no advanced mode or whitelist).
Image moderation supports a dedicated set of visual categories (including Sexual/Minors, Violence/Graphic, Self-Harm/Intent/Instructions, Harassment, Hate, and Illicit). Choose the categories you want to enforce when creating the project.
Image Categories
Image moderation analyzes visual content across the following categories:
Sexual / Sexual Minors
Detects sexually explicit or suggestive imagery, including adult content and inappropriate poses.
Violence / Violence Graphic
Identifies violent imagery including weapons, physical harm, gore, and graphic violence.
Self-Harm / Intent / Instructions
Detects depictions of self-harm, including cutting, suicide-related imagery, and eating disorders.
Harassment / Hate / Illicit
Flags hateful symbols, harassment/threats, and illicit activity when present in images.
Creating an Image Project
- Navigate to the Projects section in your console
- Open the "Add New" menu and choose "Image moderation"
- Choose which image categories to enable
- Save and get your API key
- Fine-tune category thresholds later from the project's page (each defaults to 0.5)
Important Limitations
- • No Advanced Mode: Image projects only support category-based moderation
- • No Whitelist: URL-based whitelisting isn't supported for images
- • Different Categories: Image categories differ from text (e.g., Sexual/Minors, Violence/Graphic, Illicit)
Fine-tuning Your Project
It's recommended to test and adjust your thresholds in the project playground before deploying to production.
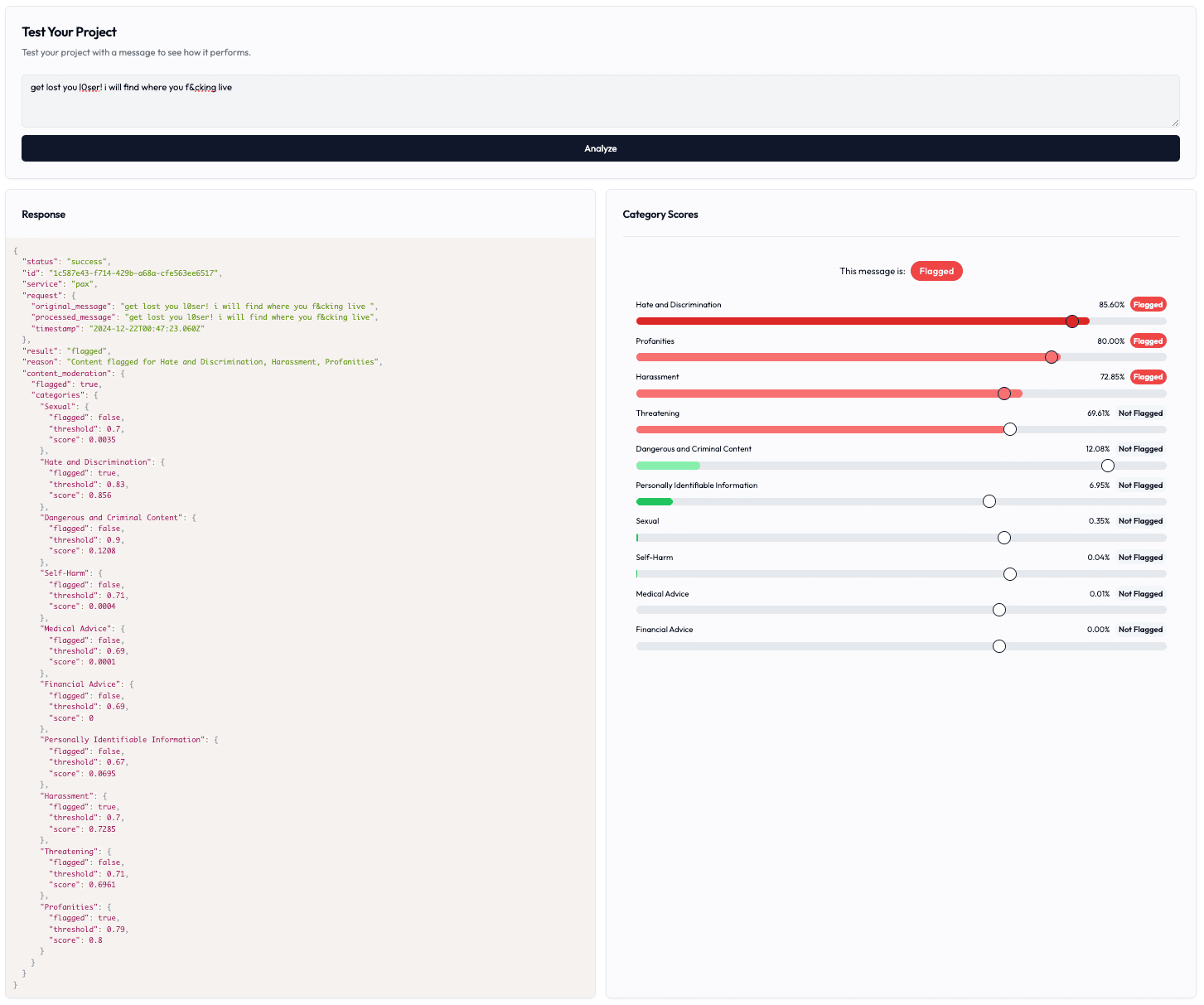
Adjusting Category Thresholds
Each moderation category has a threshold slider ranging from 0 to 1:
- 0.0-0.3: Very permissive (allows most content)
- 0.4-0.6: Balanced moderation (recommended starting point)
- 0.7-1.0: Strict moderation (flags more content)
Managing Categories
In standard mode, you can enable or disable specific moderation categories based on your needs. Disabled categories will not be checked during content moderation.
Disabling categories can improve performance but may create gaps in your content moderation. Consider your use case carefully.
Whitelist System
The whitelist feature allows you to specify terms that should never be flagged. This is particularly useful for:
- Game-specific terminology
- Character names
- Common phrases in your community
Messages containing whitelisted terms will bypass all moderation checks. Use this feature carefully to avoid creating moderation blind spots.
Testing Your Configuration
Use the project playground to:
- Test different types of content
- Adjust thresholds in real-time
- View detailed category scores
- Verify whitelist functionality
It's recommended to test with a variety of content samples that represent your actual use case, including edge cases.
Content Flagging Logic
Messages are flagged when their category score exceeds the defined threshold. Default threshold is 0.5 if not specified.
In standard mode, content is analyzed across multiple categories. Each enabled category has its own threshold and scoring:
- Each category receives a score between 0 and 1
- Content is flagged if any category score exceeds its threshold
- Profanity detection uses a rule-based filter that catches obfuscated profanities
- Other categories use AI classifier scoring
Standard Mode Response Example
{
"status": "success",
"id": "550e8400-e29b-41d4-a716-446655440000",
"service": "pax",
"result": "flagged",
"content_moderation": {
"flagged": true,
"categories": {
"Harassment": {
"flagged": true,
"score": 0.8234,
"threshold": 0.5
},
"Profanities": {
"flagged": true,
"score": 0.8,
"threshold": 0.5
},
"Threatening": {
"flagged": false,
"score": 0.2156,
"threshold": 0.5
}
}
}
}API Documentation
Complete API documentation for integrating Pax content moderation.
Authentication
All API requests require authentication using your API key in the Authorization header (recommended). For backward compatibility, you may instead pass it as an api_key field in the request body.
Authentication Header
Authorization: Bearer YOUR_API_KEYKeep your API key secure and never expose it in client-side code.
Text Moderation Endpoint
Send content for moderation using our text moderation endpoint. The API supports both standard and advanced modes based on your project configuration.
POST /api/v1/text
Request Example
const response = await fetch('https://www.paxmod.com/api/v1/text', {
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
},
body: JSON.stringify({
message: 'Text to moderate',
user_id: 'optional_user_id',
context_id: 'optional_context_id',
advanced_threshold: 0.5
})
});
const result = await response.json();Request Parameters
{
"message": "string (required)", // The text content to moderate (max 5000 characters)
"user_id": "string (optional)", // Identifier for the message author
"context_id": "string (optional)", // Context identifier (e.g., channel, room, thread)
"advanced_threshold": "number (optional)" // Custom threshold (0-1) for advanced mode
}Response Format
{
"status": "success",
"id": "unique-moderation-id",
"service": "pax",
"request": {
"original_message": "Text that was moderated",
"processed_message": "Normalized text",
"timestamp": "2024-03-21T12:00:00.000Z"
},
"result": "flagged" | "not_flagged",
"reason": "Reason for flagging or whitelisting",
"degraded": false, // true if a moderation provider was briefly unavailable
"unavailable_categories": [], // enabled categories that couldn't be scored while degraded
"content_moderation": {
"flagged": boolean,
"categories": {
"category_name": {
"flagged": boolean,
"score": number,
"threshold": number
}
}
}
}Graceful degradation
Standard-mode moderation draws on several providers. If one is briefly unavailable, the request still succeeds (HTTP 200) instead of erroring. Any enabled category that couldn't be scored is omitted from content_moderation.categories and listed in unavailable_categories, and degraded is set to true. Those categories are not flagged (fail-open), so treat a degraded: true response as reduced coverage and apply extra caution if your use case requires it.
Error Responses
{
"status": "error",
"error": {
"code": "ERROR_CODE",
"message": "Human readable message",
"details": "Detailed error description",
"timestamp": "2024-03-21T12:00:00.000Z"
}
}| HTTP | code | When |
|---|---|---|
| 401 | UNAUTHORIZED | No API key provided. |
| 401 | INVALID_API_KEY | API key is invalid or revoked. |
| 400 | EMPTY_MESSAGE | Message is empty after trimming. |
| 400 | MESSAGE_TOO_LONG | Message exceeds 5000 characters. |
| 429 | USAGE_LIMIT_EXCEEDED | Free plan's 100 messages/month limit reached. |
| 503 | LLM_SERVICE_ERROR | Advanced-mode language model was unavailable. |
| 500 | INTERNAL_SERVER_ERROR | Unexpected server error. |
Image Moderation Endpoint
Moderate images by providing publicly accessible image URLs. The API uses our advanced vision models to detect sexual, violent, self-harm, harassment, hateful, and illicit visual content.
Image Moderation Requirements
- Project must be configured with moderation_type: "image"
- Categories include Sexual/Minors, Violence/Graphic, Self-Harm/Intent/Instructions, Harassment/Threatening, Hate/Threatening, and Illicit/Violent
- Images must be publicly accessible via HTTPS URLs
- Supports common formats: JPEG, PNG, GIF, WebP
POST /api/v1/image
Request Example
const response = await fetch('https://www.paxmod.com/api/v1/image', {
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
},
body: JSON.stringify({
image_url: 'https://example.com/image.jpg',
user_id: 'user123', // optional
context_id: 'upload_456' // optional
})
});
const data = await response.json();
console.log(data);Request Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| image_url | string | Yes | Publicly accessible HTTPS URL of the image to moderate |
| user_id | string | No | Optional identifier for the user who uploaded the image |
| context_id | string | No | Optional context identifier (e.g., upload session, chat room) |
Success Response
{
"status": "success",
"id": "12f8d080-021e-4a3d-8f07-bda632fca263",
"service": "pax",
"request": {
"image_url": "https://example.com/image.jpg",
"timestamp": "2025-10-21T20:12:38.507Z"
},
"result": "not_flagged", // or "flagged"
"reason": "No moderation category thresholds exceeded",
"content_moderation": {
"flagged": false,
"categories": {
"Sexual": {
"flagged": false,
"score": 0.0023,
"threshold": 0.5
},
"Sexual/Minors": {
"flagged": false,
"score": 0.0001,
"threshold": 0.5
},
"Violence/Graphic": {
"flagged": false,
"score": 0.0145,
"threshold": 0.5
},
"Self-Harm/Intent": {
"flagged": false,
"score": 0.0012,
"threshold": 0.5
}
}
}
}Error Responses
Invalid Project Type
{
"status": "error",
"error": {
"code": "INVALID_MODERATION_TYPE",
"message": "Project not configured for image moderation",
"details": "This project is configured for text moderation. Please create a new project with image moderation type.",
"timestamp": "2025-10-21T20:12:38.507Z"
}
}Missing or Invalid Image URL
{
"status": "error",
"error": {
"code": "MISSING_IMAGE_URL",
"message": "Image URL is required",
"details": "Please provide an image_url in the request body",
"timestamp": "2025-10-21T20:12:38.507Z"
}
}